https://www.acmicpc.net/problem/10815
10815번: 숫자 카드
첫째 줄에 상근이가 가지고 있는 숫자 카드의 개수 N(1 ≤ N ≤ 500,000)이 주어진다. 둘째 줄에는 숫자 카드에 적혀있는 정수가 주어진다. 숫자 카드에 적혀있는 수는 -10,000,000보다 크거나 같고, 10,
www.acmicpc.net
import sys
ssr = sys.stdin.readline
n = int(ssr())
hc = sorted(list(map(int, ssr().split())))
m = int(ssr())
nc = list(map(int, ssr().split()))
ans = [0 for _ in range(m)]
for i in range(m):
start = 0
end = n
while start < end:
mid = (start+end)//2
if nc[i] == hc[mid]:
ans[i] = 1
break
elif nc[i] < hc[mid]:
end = mid
else:
start = mid + 1
print(*ans)저는 이진 탐색을 이용해서 풀어봤습니다. 간단하게 떠올릴 수 있는 건 O(n^2)의 이중 반복문을 사용해서 푸는 방법이지만 당연하게도 그런 풀이는 시간초과가 나겠죠. 그래서 정렬을 하더라도 O(log n)의 이진 탐색을 사용하는 쪽이 이득이라 이렇게 써봤습니다. 근데 숫자 범위도 크고 숫자 갯수도 크다보니 엄청 오래걸리는 건 똑같더라구요. 그리고 이진 탐색은 항상 범위를 정할 때 생각과 다르게 동작할 때가 좀 있어서 디버깅을 계속 해봐야 하는 것 같습니다.
200ms 근처에서 통과하신 분들이 있어서 궁금해서 풀이를 봤습니다. in 메서드를 써서 푸신 분들이 많길래 이게 그렇게 빠른가 싶어서 봤더니 in 메서드의 경우 리스트에서는 평균 O(n)의 시간복잡도를 갖지만 딕셔너리나 셋에서는 O(1)의 시간복잡도를 가진다고 나오더라구요. 이유를 모른채로 아 그렇구나~ 하고 넘어갈 수는 없으니 검색을 좀 해봤는데 딱히 제가 원하는 내용은 안보이는 거 같더라구요. 또 이럴 때 쓰는게 chatgpt 아니겠습니까. 한 번 물어봤습니다.
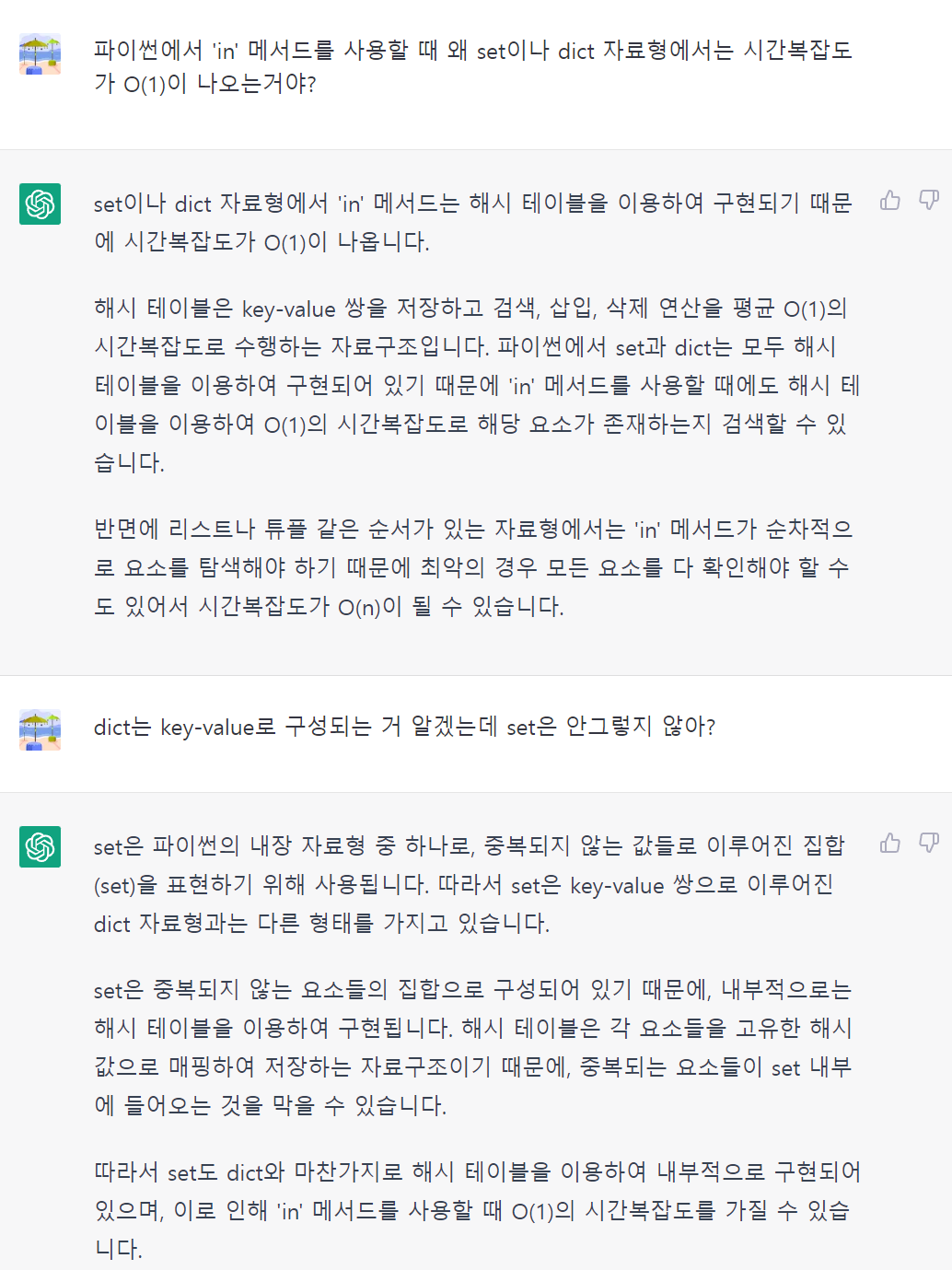
대답이 너무 훌륭하네요. set 자료구조가 어떤 해싱 방법을 통해서 구축이 되는지 까지는 잘 모르겠지만 dict와 동일하게 해시 테이블 구조로 이루어져 존재 유무를 파악하는 메서드가 빠르게 돌아간다고 합니다. 가끔 이렇게 정보를 얻기 힘들 때는 chatgpt를 적극 사용해도 좋을 것 같습니다. 다만 유머글들을 보면 정말 말도 안되는 말들을 지어내서 말하기도 하기 때문에 자명한 내용이 아닐 경우 더블 체크는 필수로 진행해 주시구요. 저는 다음에 set 자료구조의 기반부터 공부를 한 뒤에 왜 이런 결과가 나오는지 자세히 알아보고 관련 내용을 포스팅할 수 있도록 해보겠습니다.
참고로 in 메서드를 사용해서 코드를 짜면 대충 이런 느낌입니다.
n = int(input())
hc = set(input().split())
m = int(input())
nc = input().split()
for i in nc:
if i in hc:
print(1, end=' ')
else:
print(0, end=' ')'Problem Solving > BOJ' 카테고리의 다른 글
| [BOJ][Python]1476 풀이 (0) | 2023.03.01 |
|---|---|
| [BOJ][Python]27294 풀이 (0) | 2023.03.01 |
| [BOJ][Python]24262 풀이 (0) | 2023.02.27 |
| [BOJ][Python]18096 풀이 (0) | 2023.01.25 |
